Similar to, “Introduction to Transmission Lines”, I wanted to type up my notes here as a way to study some more. Hopefully there is some useful content here for someone interested in learning a bit more about algorithms.
In preparation for my midterm the topics are:
- Bounding and comparing complexities of algorithms
- Understanding asymptotic runtimes (big-o, theta, & omega)
- Finding recurrence relations and solving them
- Master Method
- Substitution
- Recursion Tree
- Dynamic Programming
- It’s basic structure
- Be familiar with:
- LCS
- Rod Cutting
- Knapsack
- LIS
- Explain why DP improves each
- Sorting & searching algorithms
Bounding and Algorithm Complexities
Every algorithm has a certain speed at which it runs. What we care about however is the efficiency and time it takes at very large values of ‘n’. The algorithms that perform the fastest for large ‘n’ usually perform better for everything except very small ‘n’. There are three terms we can use to express the various run times:
- Big-O: The upper bound, the worst case runtime the algorithm will get. This doesn’t tell us anything about the fastest it can be.
- For f(n) = O(g(n)) : There must exist positive constants, n0 and c, such that 0<=f(n)<=cg(n) for all n>=n0
- Big-Omega: The lower bound, the best case it can be. Tells us nothing about worst case.
- For f(n) = Omega(g(n)) : There must exist positive constants, n0 and c, such that 0<=c1*g(n)<=f(n)<=c2*g(n) for all n>=n0
- Big-Theta: This covers above and below the algorithm. There must exist some ‘C’ such that the runtime bounds below and above.
- For f(n) = Theta(g(n)) : There must exist positive constants, n0 and c, such that 0<=cg(n)<=f(n) for all n>=n0
When identifying these runtime you can drop the lower exponentials and slower runtimes. For example n^2+n+1 can be bound above by O(n^2) because eventually the other components will be irrelevant compared to n^2. Inversely you can prove that a statement is false pretty easily as well. Take for example 6n^3=O(n^2), and even suppose there are c and n such that: 6n^3<=cn^2. This might seem okay, but dividing each side by n^2 leaves you with: 6n <= c, which cannot hold as n increases to infinity because c is just a constant.

Asymptotic Runtimes
- O(1)
- O(loglogn)
- O(logn)
- O(log^c(n)), c>1
- O(n^c), 0<c<1
- O(n)
- O(nlogn)
- O(n^2)
- O(n^c), c>1
- O(C^n), C>1
- O(n!)
- O(n*n!)
Finding Recurrence Relations and Solving them
Master Method
The master theorem concerns recurrence relations of the form:

In the application to the analysis of a recursive algorithm, the constants and function take on the following significance:
- n is the size of the problem.
- a is the number of subproblems in the recursion.
- n/b is the size of each subproblem. (Here it is assumed that all subproblems are essentially the same size.)
- f (n) is the cost of the work done outside the recursive calls, which includes the cost of dividing the problem and the cost of merging the solutions to the subproblems.
It is possible to determine an asymptotic tight bound in these three cases:
CASE 1
Generic Form
If  where
where  (using Big O notation)
(using Big O notation)
then:

Example

As one can see from the formula above:
 , so
, so , where
, where 
Next, we see if we satisfy the case 1 condition:
 .
.
It follows from the first case of the master theorem that

(indeed, the exact solution of the recurrence relation is  , assuming
, assuming  ).
).
CASE 2
Generic form
If it is true, for some constant k ≥ 0, that:
 where
where 
then:

Example

As we can see in the formula above the variables get the following values:

- where

Next, we see if we satisfy the case 2 condition:
 , and therefore, yes,
, and therefore, yes,
So it follows from the second case of the master theorem:

Thus the given recurrence relation T(n) was in Θ(n log n).
(This result is confirmed by the exact solution of the recurrence relation, which is  , assuming .)
, assuming .)
CASE 3
Generic form
If it is true that:
 where
where 
and if it is also true that:
 for some constant
for some constant  and sufficiently large
and sufficiently large 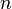 (often called the regularity condition)
(often called the regularity condition)
then:

Example

As we can see in the formula above the variables get the following values:

 , where
, where
Next, we see if we satisfy the case 3 condition:
- , and therefore, yes,
The regularity condition also holds:
 , choosing
, choosing 
So it follows from the third case of the master theorem:

Thus the given recurrence relation T(n) was in Θ(n2), that complies with the f (n) of the original formula.
(This result is confirmed by the exact solution of the recurrence relation, which is  , assuming .)
, assuming .)
Substitution
- First, guess the form of the solution
- Then use induction to show that solution works or not
- Example
- T(n)=2T(n/2)+n
- GUESS: T(n) = O(nlogn)
- Substitution requires us to to prove T(n)<=cnlogn for an appropriate c > 0. We start by assuming that this holds for all positive m<n, particularly m=n/2, yielding:
- T(n/2) <= 2[c(n/2)lg(n/2)]+n
- T(n/2) <= c(n/2)lg(n/2)+n
- T(n) <= cnlg(n/2)+n
- = cnlg(n/2)-cnlg2+n
- = cnlg-cn+n
- <= cnlgn
- Therefore: nlgn<=cnlgn for all c>1
- You then need to test boundary conditions, say T(3) find c such that it works
Recursion Tree
Basically you just draw out each level of the algorithm until you notice a pattern, you can then make a better guess of what the solution might be, and apply the substitution method.
Dynamic Programming
The Basics
Basically the goal of dynamic programming is to memoize subproblem solutions so that you only have to solve given subproblem one time, rather than multiple times. It works on algorithms that can be broken up into sub problems (recursive usually).
LCS (Longest Common Subsequence)
Given two arrays X = {A, B, C, D, E} and Y = {D, E, A, B, C}, then a third array may hold a subsequence Z = {A, B, C} or {D, E}. In the LCS we want to find the longest common subsequence possible between the two input arrays. Here we will look at the difference between using dynamic programming to solve it and not.
- Brute Force Approach
- We would enumerate every subsequence of X, check to see if it is a subsequence of Y as well, and keep track of the longest sequence.
- This approach has exponential time, making it unpractical
- Recursive DP approach
- Can get to Omega(m+n)
Rod Cutting
- This can be solved using both a naive recursive algorithm and a recursive algorithm that takes advantage of DP
- The naive approach is O(2^n) exponential, but that is because it solves the same sub problems over and over again. Using DP we can eliminate this problem
- With DP we can achieve O(n^2)
Knapsack
- The 0-1 knapsack problem is the following. A thief robbing a store finds n items. The ith item is worth i dollars and weighs wi pounds, where i and wi are integers. The thief wants to take as valuable a load as possible, but he can carry at most W pounds in his knapsack, for some integer W . Which items should he take?
- The greedy approach won’t work on 0-1 knapsack problem as capacity throws things off, but it does work on the fractional knapsack problem.
- Has many suboptimal solutions, which hints that it may be useful to use DP.
LIS
- In computer science, the longest increasing subsequence problem is to find a subsequence of a given sequence in which the subsequence’s elements are in sorted order, lowest to highest, and in which the subsequence is as long as possible. This subsequence is not necessarily contiguous, or unique. Longest increasing subsequences are studied in the context of various disciplines related to mathematics, including algorithmics, random matrix theory, representation theory, and physics.[1]The longest increasing subsequence problem is solvable in time O(n log n), where n denotes the length of the input sequence.
Sorting and Searching Algorithms
Insertion Sort
Insertion sort is a simple sorting algorithm that builds the final sorted array (or list) one item at a time. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort. However, insertion sort provides several advantages:
- Simple implementation: Bentley shows a three-line C version, and a five-line optimized version[1]:116
- Efficient for (quite) small data sets
- More efficient in practice than most other simple quadratic (i.e., O(n2)) algorithms such as selection sort or bubble sort
- Adaptive, i.e., efficient for data sets that are already substantially sorted: the time complexity is O(nk) when each element in the input is no more than k places away from its sorted position
- Stable; i.e., does not change the relative order of elements with equal keys
- In-place; i.e., only requires a constant amount O(1) of additional memory space
- Online; i.e., can sort a list as it receives it
When people manually sort something (for example, a deck of playing cards), most use a method that is similar to insertion sort.[2]
Merge Sort
In computer science, merge sort (also commonly spelled mergesort) is an O(n log n) comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the implementation preserves the input order of equal elements in the sorted output. Mergesort is a divide and conquer algorithm
Conceptually, a merge sort works as follows:
- Divide the unsorted list into n sublists, each containing 1 element (a list of 1 element is considered sorted).
- Repeatedly merge sublists to produce new sorted sublists until there is only 1 sublist remaining. This will be the sorted list.
There are Top-down and Bottom-up methods for this algorithm.
Binary Search
In computer science, a binary search or half-interval search algorithm finds the position of a specified input value (the search “key”) within an array sorted by key value.[1][2] For binary search, the array should be arranged in ascending or descending order. In each step, the algorithm compares the search key value with the key value of the middle element of the array. If the keys match, then a matching element has been found and its index, or position, is returned. Otherwise, if the search key is less than the middle element’s key, then the algorithm repeats its action on the sub-array to the left of the middle element or, if the search key is greater, on the sub-array to the right. If the remaining array to be searched is empty, then the key cannot be found in the array and a special “not found” indication is returned.
A binary search halves the number of items to check with each iteration, so locating an item (or determining its absence) takes logarithmic time. A binary search is a dichotomic divide and conquer search algorithm.
References
http://en.wikipedia.org/wiki/Master_theorem
http://en.wikipedia.org/wiki/Longest_common_subsequence_problem
Misc Wikipedia pages…
